
As mentioned in my previous post (Azure OpenAI), “Enterprise GPT” is an integration of Azure OpenAI with other cognitive services aimed at providing a ChatGPT-like experience based on internal company data.
To achieve this goal, Azure OpenAI is paired with Azure Cognitive Search to provide answers based on internal company documents (HR, legal, marketing, etc.). This combination relies on the ability of Cognitive Search to index, understand, and return data, and ChatGPT’s ability to interact in natural language to answer questions and hold a conversation.

Cognitive Search Indexation
Enterprise GPT relies on document indexing to provide the response. Azure Cognitive Search can index documents from a wide variety of sources, such as Blob Storage, databases (SQL Server, Cosmos DB), datalakes, SharePoint (still in Preview), and many others.
Indexing occurs in several stages (Indexer overview):

- Document cracking : opening documents and extracting content (e.g., for a PDF, extracting text, images, and metadata). For databases, the indexer retrieves non-binary content corresponding to the fields in the records.
- Input Field mapping : defining the fields from the source. This becomes more relevant if there are different mappings between the source and the destination.
- Skillset execution : an optional stage that uses built-in processes such as OCR, translation, and keyphrase extraction.
- Output Field mapping : defining the fields for the destination.
- Push into Index.
Once the search index is created, it is necessary to ensure that ChatGPT understands the natural language query and is capable of processing it to query the index.
How to chat with your data ?
The ability to interact with company data relies on ChatGPT, which serves as an intermediary between the user and the Cognitive Search index. In practice, the user enters their query in the dedicated interface, and several approaches have been designed for this purpose:
- The user’s query contains enough information to directly query the index; this is referred to as the Retrieve-then-Read approach (single-shot Q&A scenarios). ChatGPT optimizes the query to search the index and retrieve the top n documents, and constructs a response based on the index’s answer, the user’s question, and the instructions.
- The user’s query does not contain enough information to query the index. ChatGPT can use the conversation history to gather context and generate a query. However, sometimes the conversation history alone is not sufficient to obtain enough context.
- An interesting approach is Read-Decompose-Ask, as it is now known that asking an LLM model to decompose the answers into multiple smaller tasks improves the quality of the responses and avoids certain errors. These tasks can vary (classic Q&A, external data lookup, Chain of Thought prompting, etc.).
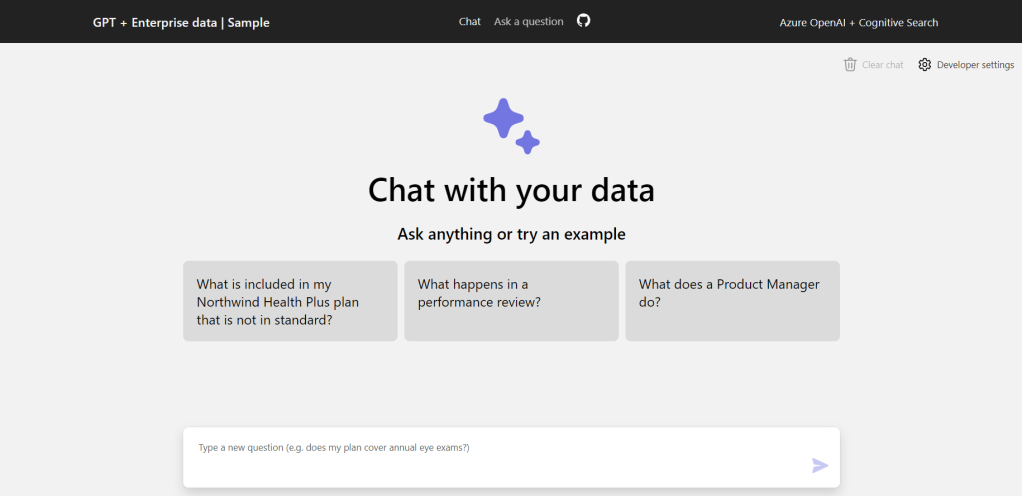
The image below presents the conversation between an employee of the fictional company Contoso and ChatGPT regarding health insurance.

The responses provided by ChatGPT are presented with accompanying citations from documents supporting the answer. The section of the document can be viewed by clicking on the provided link. In the same interface, one can access the thought process of ChatGPT. This process consists of the user query, the prompt (general instructions regarding the behavior of ChatGPT), the documents returned by the index, the intermediate results… all leading to the response provided to the user.
Knowing that the quality of the response returned by GPT depends on the quality of the information retrieved from the Cognitive Search index, here are a few options to consider:
- Semantic ranking: this improves accuracy by reclassifying query results on the index. It focuses on the semantic meaning of the terms composing the query; using deep learning techniques.
- Document chunking: the chunk size is crucial for document reading by ChatGPT. A too small chunk size can result in a lack of context. Conversely, a too large size can make it difficult to locate relevant information. A good compromise appears to be breaking the text into small paragraphs (a few sentences).
- Summarization: the size of the chunks returned by Cognitive Search can be problematic when considering multiple documents. One solution is to use Semantic Captions (a summary generation step directly supported by Cognitive Search) or hit-highlighting (a way to extract snippets).
- Follow-up questions: this allows to suggest questions that may be interesting for the user.

The combination of GPT’s contextual understanding and Azure Cognitive Search’s intelligent search capabilities enables users to find precise answers, insights, and relevant documents with greater efficiency. This reduces the time spent on manual information retrieval and eliminates the need to sift through numerous documents manually.
Additionally, the semantic understanding provided by GPT allows for more accurate query understanding, even with complex or ambiguous queries. The search results can be fine-tuned and ranked based on relevance, ensuring that the most pertinent information appears at the top of the search results.
ElasticSearch GPT
If you are interested in the topic of Enterprise GPT (or Enterprise Search), I suggest a topic on ElasticSearch, which offers its own version of integrating ChatGPT with enterprise data: ElasticSearch with GPT. This integration is quite similar to the one achieved with Cognitive Search, in the sense that ElasticSearch is an analytical search engine based on indexing.


Leave a comment