
Some time ago, I was writing about how OpenAI and Cognitive Search could change enterprise search. Today, I will discuss another approach : vector databases for enterprise search; and how the generation of answers augmented by document retrieval (RAG) can rely on vector comparison.
I will briefly explain the concepts of embeddings and vectorization, and then explain how vector similarity can assist us in our information retrieval.
Embeddings & Vectors
Word embeddings are a type of representation used in natural language processing (NLP) and machine learning to capture the semantic meaning of words in a numerical format. They are dense vector representations of words, where each word is represented by a continuous-valued vector in a high-dimensional space. The concept behind word embeddings is to create a distributed representation of words, meaning that words with similar meanings are represented by vectors that are close to each other in the embedding space (vectorial space – see illustration below).

Word embeddings have several advantages. Firstly, they capture semantic relationships between words. For example, words like “cat” and “dog” would have similar vector representations because they are both animal-related terms. Secondly, they can handle out-of-vocabulary words by providing meaningful representations even for words that were not seen during training, based on the context in which they appear.
Word embeddings have been widely used in various NLP tasks, including sentiment analysis, text classification, machine translation, named entity recognition, and question-answering systems. They provide a way to incorporate semantic knowledge into machine learning models and improve their performance in understanding and generating human language.
In OpenAI (or AOAI), there are models specialized in text content embedding (ex: text-embedding-ada-002). However, vectorization can be applied to much more than just text. Models exist to vectorize audio, image, or video content.
And once vector generation by embedding models is complete, the question of storing these vectors arises. This is where vector databases come into play.
Vector Databases
A vector database is a system for efficient storage and retrieval of vector representations. It enables fast and accurate similarity comparisons. The database includes an indexing structure for efficient search operations, which can use techniques like k-d trees or locality-sensitive hashing (LSH). It is commonly used in applications where similarity search or nearest neighbor search is required.
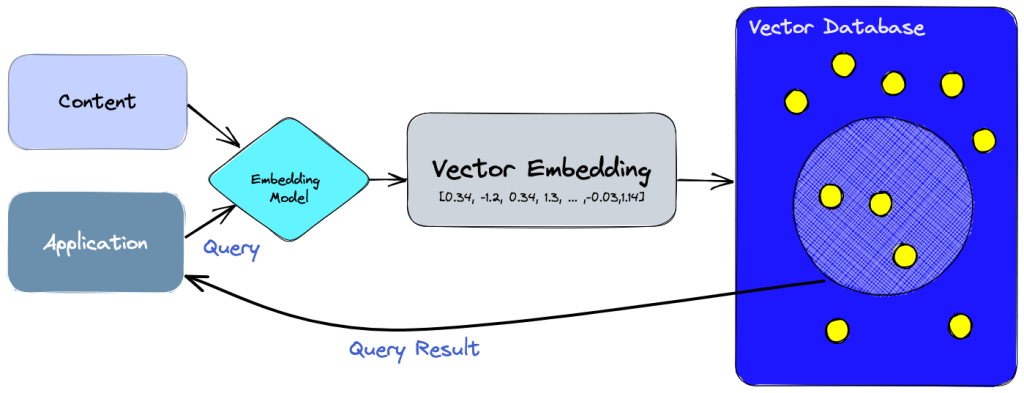
For instance, cosine similarity is a commonly used measure to compare vectors in a vector database. It quantifies the similarity between two vectors based on the cosine of the angle between them. Cosine similarity ranges from -1 to 1, with 1 indicating identical vectors, 0 indicating orthogonal or unrelated vectors, and -1 indicating completely opposite vectors (to read more : Cosine Similarity – Understanding the math and how it works?).

When performing a query in a vector database, the query vector is compared to the stored vectors using cosine similarity. The vectors with the highest cosine similarity scores are considered the most similar to the query vector and are returned as the nearest neighbors.
By leveraging the efficiency of the indexing structure and the effectiveness of cosine similarity, vector databases can quickly retrieve similar vectors, enabling tasks such as content-based search, recommendation systems, and clustering in various domains, including text, audio, image, and video data.
VectorSearch
If you have been following me on embeddings and vector databases, you can see that vectorization can enable the retrieval of relevant content (similar in vector sense) in the context of search with OpenAI. Here is a general diagram :

- The user asks a question to their AI assistant (OpenAI).
- The query is vectorized (with embeddings model).
- The query vector is compared to the vector database. Using similarity measures, the most relevant content is retrieved.
- The AI assistant uses the content retrieved from the vector search to generate a response.
- The AI shares the answer with the user.
Many implementations of VectorSearch have emerged. The main variations lie in the choice of the vector database and the implementation of the search by OpenAI. For those who want to read more, I recommend checking out these Github repositories:
- Azure CosmosDB for MongoDB vCore : repo.
- Azure CosmosDB & Redis : repo.
- Pinecone SemanticSearch : repo.
- Redis Product Search : repo.
In conclusion, I would be happy to discuss with you your feedback, implementation ideas, and experiences on VectorSearch.

Leave a comment